Controversy Surrounds Google Print For Libraries
- by Michael Stillman
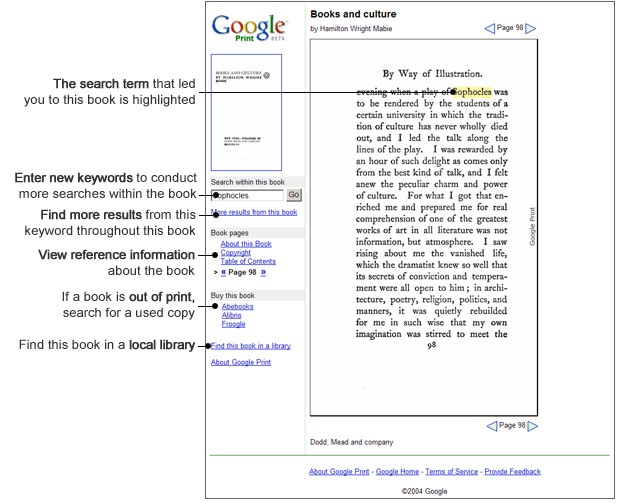
Sample of a Google Print for Libraries search result from the Google website.
By Michael Stillman
Back in December 2004, the search engine company Google announced a massive project to digitize old books. The project, named "Google Print for Libraries," involved scanning collections from five libraries, the University of Michigan, Stanford, Harvard, Oxford, and the New York Public Library. As many as two million old books are to be scanned during this process. The full text of these books would then be made available to the public online. Rare old books, virtually unobtainable by anyone but scholars with access to rare book collections, would become available to everyone. A typical student living in North Dakota or East Timor could have access formerly reserved to great scholars.
What could possibly be wrong with such a wondrous development? Well, the biggest issue that comes to mind is copyrights. Book publishers own copyrights to many works, and they are probably about as excited by the prospect of people viewing their books for free as music publishers are happy about people downloading their music free. Not a whole lot.
Google also announced a similar program for publishers. Google will upload copies of newer books to their database, and allow searchers to view snippets from these books. However, snippets are all you see. If you want to read the entire book, you have to buy it, and Google provides links to where to buy those books. It's great advertising for the publishers. Even more importantly, the publishers have to volunteer to have their books posted within the Google Print for Publishers system. No controversy here. If you don't want you books posted, don't volunteer. They won't show up.
However, Google Print for Libraries is not based on permission. Google is simply scanning those old books it chooses. These books fall into two categories: those that are clearly old enough so that all copyrights have expired, and those which either are or may still be under copyright protection. It's hard to argue about the former. Apparently Google regards books published in the U.S. before 1923 or internationally before 1900 to be clearly out of copyright. However, some of the material within the collections being scanned is more recent than this, and it seems Google intends to scan some of these works as well. We understand that they have voiced a willingness to eliminate material a copyright owner requests be removed, but this requires an affirmative step by that owner, who may not be aware it has works being copied. It is the use of still copyrighted material that had led to protests, most notably by the Association of American University Presses, but others such as the Association of Learned and Professional Society Publishers as well. The ALPSP recently called on Google to "...cease unlicensed digitisation of copyright materials with immediate effect..."